

General audience texts
Besides the scholarly publications listed below, I have written many texts in English and German. My more notable German texts appeared by DNIP.ch. I also maintain document collections intended for a broad audience:
Scholarly publications
Up-to-date citation counts (provided by Google Scholar). List of patents granted.
2015
Thomas Zink; Marcel Waldvogel
Efficient hash tables for network applications Journal Article
In: SpringerPlus, vol. 4, no. 222, pp. 1-19, 2015.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables | Links:
@article{Zink2015EHT,
title = {Efficient hash tables for network applications},
author = {Thomas Zink and Marcel Waldvogel},
editor = {Springer},
url = {https://netfuture.ch/wp-content/uploads/2015/05/zink2015eht.pdf},
doi = {10.1186/s40064-015-0958-y},
year = {2015},
date = {2015-05-15},
urldate = {1000-01-01},
journal = {SpringerPlus},
volume = {4},
number = {222},
pages = {1-19},
abstract = {Hashing has yet to be widely accepted as a component of hard real-time systems and hardware implementations, due to still existing prejudices concerning the unpredictability of space and time requirements resulting from collisions. While in theory perfect hashing can provide optimal mapping, in practice, finding a perfect hash function is too expensive, especially in the context of high-speed applications.
The introduction of hashing with multiple choices, d-left hashing and probabilistic table summaries, has caused a shift towards deterministic DRAM access. However, high amounts of rare and expensive high-speed SRAM need to be traded off for predictability, which is infeasible for many applications.
In this paper we show that previous suggestions suffer from the false precondition of full generality. Our approach exploits four individual degrees of freedom available in many practical applications, especially hardware and high-speed lookups. This reduces the requirement of on-chip memory up to an order of magnitude and guarantees constant lookup and update time at the cost of only minute amounts of additional hardware. Our design makes efficient hash table implementations cheaper, more predictable, and more practical.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {article}
}
The introduction of hashing with multiple choices, d-left hashing and probabilistic table summaries, has caused a shift towards deterministic DRAM access. However, high amounts of rare and expensive high-speed SRAM need to be traded off for predictability, which is infeasible for many applications.
In this paper we show that previous suggestions suffer from the false precondition of full generality. Our approach exploits four individual degrees of freedom available in many practical applications, especially hardware and high-speed lookups. This reduces the requirement of on-chip memory up to an order of magnitude and guarantees constant lookup and update time at the cost of only minute amounts of additional hardware. Our design makes efficient hash table implementations cheaper, more predictable, and more practical.
2009
Thomas Zink; Marcel Waldvogel
Packet Forwarding using Efficient Hash Tables Technical Report
University of Konstanz Konstanz, Germany, no. KN-2009-DISY-01, 2009.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables | Links:
@techreport{Zink2009Packet,
title = {Packet Forwarding using Efficient Hash Tables},
author = {Thomas Zink and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2015/02/zink2009packet.pdf},
year = {2009},
date = {2009-04-03},
urldate = {1000-01-01},
number = {KN-2009-DISY-01},
address = {Konstanz, Germany},
institution = {University of Konstanz},
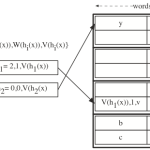
abstract = {This report discusses our proposed improvements to Fast Hash Tables (FHT) which we name ’Efficient Hash Table’ (EHT) where ’efficient’ relates to both memory efficiency and lookup performance. The mechanism we use to design the EHT lead to improvements in terms of SRAM memory requirements by the factor of ten over the FHT. Our results back the theoretical analysis and allow accurate predictions. A cost function is provided that allows the adjustment of EHT parameter to different user requirements.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {techreport}
}
2007
Paul Hurley; Marcel Waldvogel
Bloom Filters: One Size Fits All? Proceedings Article
In: Proceedings of IEEE LCN 2007, pp. 183-190, 2007, ISSN: 0742-1303.
Abstract | BibTeX | Tags: Bloom Filters, Hash Tables | Links:
@inproceedings{Hurley2007Bloom,
title = {Bloom Filters: One Size Fits All?},
author = {Paul Hurley and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2007/waldvogel07bloom.pdf},
issn = {0742-1303},
year = {2007},
date = {2007-06-17},
urldate = {1000-01-01},
booktitle = {Proceedings of IEEE LCN 2007},
journal = {lcn},
pages = {183-190},
abstract = {Bloom filters impress by their sheer elegance and have become a widely and indiscriminately used tool in network applications, although, as we show, their performance can often be far from optimal. Notably in application areas where false negatives are tolerable, other techniques can clearly be better. We show that, at least for a specific area in the parameter space, Bloom filters are significantly outperformed even by a simple scheme. We show that many application areas where Bloom filters are deployed do not require the strong policy of no false negatives and sometimes even prefer false negatives. We analyze, through modelling, how far Bloom filters are from the optimal and then examine application specific issues in a distributed web caching scenario. We hope to open up and seed discussion towards domain-specific alternatives to Bloom filters while perhaps sparking ideas for a general-purpose alternative.},
keywords = {Bloom Filters, Hash Tables},
pubstate = {published},
tppubtype = {inproceedings}
}
2001
Marcel Waldvogel; George Varghese; Jon Turner; Bernhard Plattner
Scalable High-Speed Prefix Matching Journal Article
In: Transaction on Computer Systems, vol. 19, no. 4, pp. 440-482, 2001.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables | Links:
@article{Waldvogel2001Scalable,
title = {Scalable High-Speed Prefix Matching},
author = {Marcel Waldvogel and George Varghese and Jon Turner and Bernhard Plattner},
url = {https://netfuture.ch/wp-content/uploads/2001/waldvogel01scalable.pdf},
year = {2001},
date = {2001-06-21},
urldate = {1000-01-01},
journal = {Transaction on Computer Systems},
volume = {19},
number = {4},
pages = {440-482},
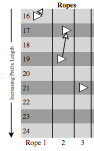
abstract = {Finding the longest matching prefix from a database of keywords is an old problem with a number of applications, ranging from dictionary searches to advanced memory management to computational geometry. But perhaps today's most frequent best matching prefix lookups occur in the Internet, when forwarding packets from router to router. Internet traffic volume and link speeds are rapidly increasing; at the same time, a growing user population is increasing the size of routing tables against which packets must be matched. Both factors make router prefix matching extremely performance critical.In this paper, we introduce a taxonomy for prefix matching technologies, which we use as a basis for describing, categorizing, and comparing existing approaches. We then present in detail a fast scheme using binary search over hash tables, which is especially suited for matching long addresses, such as the 128 bit addresses proposed for use in the next generation Internet Protocol, IPv6. We also present optimizations that exploit the structure of existing databases to further improve access time and reduce storage space.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {article}
}
2000
Marcel Waldvogel
Multi-Dimensional Prefix Matching Using Line Search Proceedings Article
In: Proceedings of IEEE Local Computer Networks, pp. 200-207, Tampa, FL, USA, 2000.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables, Quality of Service | Links:
@inproceedings{Waldvogel2000Multi-Dimensional,
title = {Multi-Dimensional Prefix Matching Using Line Search},
author = {Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2000/waldvogel00multidimensional.pdf},
year = {2000},
date = {2000-11-01},
urldate = {1000-01-01},
booktitle = {Proceedings of IEEE Local Computer Networks},
pages = {200-207},
address = {Tampa, FL, USA},
abstract = {With the increasing popularity of firewalls, virtual private networks (VPNs) and Quality of Service (QoS) routing, packet classification becomes increasingly important in the Internet. The high-performance solutions known so far strongly rely on certain properties of the filter database to match against, such as a small number of distinct prefixes or the absence of conflicts. In this paper, we present Line Search as a two-dimensional generalization of the one-dimensional binary search on prefix lengths, exploiting the advantage given by the different approach therein. This algorithm also works best on the filter databases that are expected to occur most often, but degrades gracefully when these assumptions no longer hold. We also show how to efficiently extend the algorithm to a complete five-dimensional Internet Protocol (IP) and transport header match.},
keywords = {Fast Routers, Hash Tables, Quality of Service},
pubstate = {published},
tppubtype = {inproceedings}
}
Marcel Waldvogel
Fast Longest Prefix Matching: Algorithms, Analysis, and Applications Book
Shaker Verlag, Aachen, Germany, 2000.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables | Links:
@book{Waldvogel2000Fast,
title = {Fast Longest Prefix Matching: Algorithms, Analysis, and Applications},
author = {Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2000/waldvogel00fast.pdf},
year = {2000},
date = {2000-01-01},
urldate = {1000-01-01},
publisher = {Shaker Verlag},
address = {Aachen, Germany},
abstract = {Many current problems demand efficient best matching algorithms. Network devices alone show several applications. They need to determine a \emph{longest matching prefix} for packet routing or establishment of virtual circuits. In integrated services packet networks, packets need to be classified by trying to find the \emph{most specific match} from a large number of patterns, each possibly containing wildcards at arbitrary positions. Other areas of applications include such diverse areas as geographical information systems (GIS) and persistent databases.
We describe a class of best matching algorithms based on slicing perpendicular to the patterns and performing a modified binary search over these slices. We also analyze their complexity and performance. We then introduce schemes that allow the algorithm to ``learn'' the structure of the database and adapt itself to it. Furthermore, we show how to efficiently implement our algorithm both using general-purpose hardware and using software running on popular personal computers and workstations.
The research presented herein was originally driven by current demands in the Internet. Since the advent of the World Wide Web, the number of users, hosts, domains, and networks connected to the Internet seems to be exploding. Not surprisingly, network traffic at major exchange points is doubling every few months. The Internet is a packet network, where each data packet is passed from a router to the next in the chain, until it reaches destination. For versatility and efficient utilization of the available transmission bandwidth, each router performs its decision where to forward a packet as independent of the other routers and the other packets for the same destination as possible.
Five key factors are required to keep pace if the Internet is to continue to provide good service:
<ol>
<li>higher link speeds,</li>
<li>better router data throughput,</li>
<li>faster packet forwarding rates,</li>
<li>quick adaptation to topology and load changes, and</li>
<li>the support for Quality-of-Service (QoS).</li>
</ol>
Solutions for the first two are readily available: fiber-optic cables using wavelength-division multiplexing (WDM) and switching backplane interconnects. We present longest matching prefix techniques which help solving the other three factors. They allow for a high rate of forwarding decisions, quick updates, and can be extended to classify packets based on multiple fields.
The best known longest matching prefix solutions require memory accesses proportional to the length of the addresses. Our new algorithm uses binary search on hash tables organized by prefix lengths and scales very well as address and routing table sizes increase: independent of the table size, it requires a worst case time of log_{2}(\textit{address bits\textit{) hash lookups. Thus only 5 hash lookups are needed for the current Internet protocol version 4 (IPv4) with 32 address bits and 7 for the upcoming IPv6 with 128 address bits. We also introduce \emph{mutating binary search} and other optimizations that, operating on the largest available databases, reduce the worst case to 4 hashes and allow the majority of addresses to be found with at most 2 hashes. We expect similar improvements to hold for IPv6.
We extend these results to find the best match for a tuple of multiple fields of the packet's header, as required for QoS support. We also show the versatility of the resulting algorithms by using it for such diverse applications as geographical information systems, memory management, garbage collection, persistent object-oriented databases, keeping distributed databases synchronized, and performing web-server access control.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {book}
}
We describe a class of best matching algorithms based on slicing perpendicular to the patterns and performing a modified binary search over these slices. We also analyze their complexity and performance. We then introduce schemes that allow the algorithm to “learn” the structure of the database and adapt itself to it. Furthermore, we show how to efficiently implement our algorithm both using general-purpose hardware and using software running on popular personal computers and workstations.
The research presented herein was originally driven by current demands in the Internet. Since the advent of the World Wide Web, the number of users, hosts, domains, and networks connected to the Internet seems to be exploding. Not surprisingly, network traffic at major exchange points is doubling every few months. The Internet is a packet network, where each data packet is passed from a router to the next in the chain, until it reaches destination. For versatility and efficient utilization of the available transmission bandwidth, each router performs its decision where to forward a packet as independent of the other routers and the other packets for the same destination as possible.
Five key factors are required to keep pace if the Internet is to continue to provide good service:
- higher link speeds,
- better router data throughput,
- faster packet forwarding rates,
- quick adaptation to topology and load changes, and
- the support for Quality-of-Service (QoS).
Solutions for the first two are readily available: fiber-optic cables using wavelength-division multiplexing (WDM) and switching backplane interconnects. We present longest matching prefix techniques which help solving the other three factors. They allow for a high rate of forwarding decisions, quick updates, and can be extended to classify packets based on multiple fields.
The best known longest matching prefix solutions require memory accesses proportional to the length of the addresses. Our new algorithm uses binary search on hash tables organized by prefix lengths and scales very well as address and routing table sizes increase: independent of the table size, it requires a worst case time of log2(address bits) hash lookups. Thus only 5 hash lookups are needed for the current Internet protocol version 4 (IPv4) with 32 address bits and 7 for the upcoming IPv6 with 128 address bits. We also introduce mutating binary search and other optimizations that, operating on the largest available databases, reduce the worst case to 4 hashes and allow the majority of addresses to be found with at most 2 hashes. We expect similar improvements to hold for IPv6.
We extend these results to find the best match for a tuple of multiple fields of the packet’s header, as required for QoS support. We also show the versatility of the resulting algorithms by using it for such diverse applications as geographical information systems, memory management, garbage collection, persistent object-oriented databases, keeping distributed databases synchronized, and performing web-server access control.
Jonathan Turner; George Varghese; Marcel Waldvogel
Scalable High Speed IP Routing Lookups Miscellaneous
U.S. Patent Number 6,018,524, 2000.
BibTeX | Tags: Fast Routers, Hash Tables
@misc{Turner2000Scalable,
title = {Scalable High Speed IP Routing Lookups},
author = {Jonathan Turner and George Varghese and Marcel Waldvogel},
year = {2000},
date = {2000-01-01},
urldate = {1000-01-01},
howpublished = {U.S. Patent Number 6,018,524},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {misc}
}
1998
V. Srinivasan; George Varghese; Subhash Suri; Marcel Waldvogel
Fast and Scalable Layer Four Switching Proceedings Article
In: Proceedings of ACM SIGCOMM, pp. 191-202, 1998.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables, Quality of Service | Links:
@inproceedings{Srinivasan1998Fast,
title = {Fast and Scalable Layer Four Switching},
author = {V. Srinivasan and George Varghese and Subhash Suri and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/1998/srinivasan98fast.pdf},
year = {1998},
date = {1998-09-01},
urldate = {1000-01-01},
booktitle = {Proceedings of ACM SIGCOMM},
pages = {191-202},
abstract = { In Layer Four switching, the route and resources allocated to a packet are determined by the destination address as well as other header fields of the packet such as source address, TCP and UDP port numbers. Layer Four switching unifies firewall processing, RSVP style resource reservation filters, QoS Routing, and normal unicast and multicast forwarding into a single framework. In this framework, the forwarding database of a router consists of a potentially large number of filters on key header fields. A given packet header can match multiple filters, so each filter is given a cost, and the packet is forwarded using the least cost matching filter. In this paper, we describe two new algorithms for solving the least cost matching filter problem at high speeds. Our first algorithm is based on a grid-of-tries construction and works optimally for processing filters consisting of two prefix fields (such as destination-source filters) using linear space. Our second algorithm, cross-producting, provides fast lookup times for arbitrary filters but potentially requires large storage. We describe a combination scheme that combines the advantages of both schemes. The combination scheme can be optimized to handle pure destination prefix filters in 4 memory accesses, destination-source filters in 8 memory accesses worst case, and all other filters in 11 memory accesses in the typical case.},
keywords = {Fast Routers, Hash Tables, Quality of Service},
pubstate = {published},
tppubtype = {inproceedings}
}
1997
Marcel Waldvogel; George Varghese; Jon Turner; Bernhard Plattner
Scalable High Speed IP Routing Table Lookups Proceedings Article
In: Proceedings of ACM SIGCOMM, pp. 25-36, 1997.
Abstract | BibTeX | Tags: Fast Routers, Hash Tables | Links:
@inproceedings{Waldvogel1997Scalable,
title = {Scalable High Speed IP Routing Table Lookups},
author = {Marcel Waldvogel and George Varghese and Jon Turner and Bernhard Plattner},
url = {https://netfuture.ch/wp-content/uploads/1997/waldvogel97scalable.pdf},
year = {1997},
date = {1997-08-28},
urldate = {1000-01-01},
booktitle = {Proceedings of ACM SIGCOMM},
pages = {25-36},
abstract = {Internet address lookup is a challenging problem because of increasing routing table sizes, increased traffic, higher speed links, and the migration to 128 bit IPv6 addresses. IP routing lookup requires computing the best matching prefix, for which standard solutions like hashing were believed to be inapplicable. The best existing solution we know of, BSD radix tries, scales badly as IP moves to 128 bit addresses. Our paper describes a new algorithm for best matching prefix using binary search on hash tables organized by prefix lengths. Our scheme scales very well as address and routing table sizes increase: independent of the table size, it requires a worst case time of log_{2}(\textit{address bits}) hash lookups. Thus only 5 hash lookups are needed for IPv4 and 7 for IPv6. We also introduce Mutating Binary Search and other optimizations that, for a typical IPv4 backbone router with over 33,000 entries, considerably reduce the average number of hashes to less than 2, of which one hash can be simplified to an indexed array access. We expect similar average case behavior for IPv6.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {inproceedings}
}