
Links
Abstract
Many current problems demand efficient best matching algorithms. Network devices alone show several applications. They need to determine a longest matching prefix for packet routing or establishment of virtual circuits. In integrated services packet networks, packets need to be classified by trying to find the most specific match from a large number of patterns, each possibly containing wildcards at arbitrary positions. Other areas of applications include such diverse areas as geographical information systems (GIS) and persistent databases.
We describe a class of best matching algorithms based on slicing perpendicular to the patterns and performing a modified binary search over these slices. We also analyze their complexity and performance. We then introduce schemes that allow the algorithm to “learn” the structure of the database and adapt itself to it. Furthermore, we show how to efficiently implement our algorithm both using general-purpose hardware and using software running on popular personal computers and workstations.
The research presented herein was originally driven by current demands in the Internet. Since the advent of the World Wide Web, the number of users, hosts, domains, and networks connected to the Internet seems to be exploding. Not surprisingly, network traffic at major exchange points is doubling every few months. The Internet is a packet network, where each data packet is passed from a router to the next in the chain, until it reaches destination. For versatility and efficient utilization of the available transmission bandwidth, each router performs its decision where to forward a packet as independent of the other routers and the other packets for the same destination as possible.
Five key factors are required to keep pace if the Internet is to continue to provide good service:
- higher link speeds,
- better router data throughput,
- faster packet forwarding rates,
- quick adaptation to topology and load changes, and
- the support for Quality-of-Service (QoS).
Solutions for the first two are readily available: fiber-optic cables using wavelength-division multiplexing (WDM) and switching backplane interconnects. We present longest matching prefix techniques which help solving the other three factors. They allow for a high rate of forwarding decisions, quick updates, and can be extended to classify packets based on multiple fields.
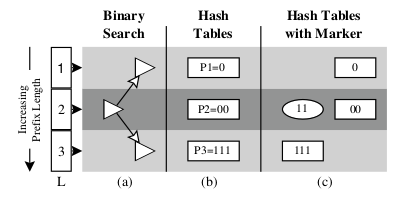
The best known longest matching prefix solutions require memory accesses proportional to the length of the addresses. Our new algorithm uses binary search on hash tables organized by prefix lengths and scales very well as address and routing table sizes increase: independent of the table size, it requires a worst case time of log2(address bits) hash lookups. Thus only 5 hash lookups are needed for the current Internet protocol version 4 (IPv4) with 32 address bits and 7 for the upcoming IPv6 with 128 address bits. We also introduce mutating binary search and other optimizations that, operating on the largest available databases, reduce the worst case to 4 hashes and allow the majority of addresses to be found with at most 2 hashes. We expect similar improvements to hold for IPv6.
We extend these results to find the best match for a tuple of multiple fields of the packet’s header, as required for QoS support. We also show the versatility of the resulting algorithms by using it for such diverse applications as geographical information systems, memory management, garbage collection, persistent object-oriented databases, keeping distributed databases synchronized, and performing web-server access control.
BibTeX (Download)
@book{Waldvogel2000Fast,
title = {Fast Longest Prefix Matching: Algorithms, Analysis, and Applications},
author = {Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2000/waldvogel00fast.pdf},
year = {2000},
date = {2000-01-01},
urldate = {1000-01-01},
publisher = {Shaker Verlag},
address = {Aachen, Germany},
abstract = {Many current problems demand efficient best matching algorithms. Network devices alone show several applications. They need to determine a \emph{longest matching prefix} for packet routing or establishment of virtual circuits. In integrated services packet networks, packets need to be classified by trying to find the \emph{most specific match} from a large number of patterns, each possibly containing wildcards at arbitrary positions. Other areas of applications include such diverse areas as geographical information systems (GIS) and persistent databases.
We describe a class of best matching algorithms based on slicing perpendicular to the patterns and performing a modified binary search over these slices. We also analyze their complexity and performance. We then introduce schemes that allow the algorithm to ``learn'' the structure of the database and adapt itself to it. Furthermore, we show how to efficiently implement our algorithm both using general-purpose hardware and using software running on popular personal computers and workstations.
The research presented herein was originally driven by current demands in the Internet. Since the advent of the World Wide Web, the number of users, hosts, domains, and networks connected to the Internet seems to be exploding. Not surprisingly, network traffic at major exchange points is doubling every few months. The Internet is a packet network, where each data packet is passed from a router to the next in the chain, until it reaches destination. For versatility and efficient utilization of the available transmission bandwidth, each router performs its decision where to forward a packet as independent of the other routers and the other packets for the same destination as possible.
Five key factors are required to keep pace if the Internet is to continue to provide good service:
<ol>
<li>higher link speeds,</li>
<li>better router data throughput,</li>
<li>faster packet forwarding rates,</li>
<li>quick adaptation to topology and load changes, and</li>
<li>the support for Quality-of-Service (QoS).</li>
</ol>
Solutions for the first two are readily available: fiber-optic cables using wavelength-division multiplexing (WDM) and switching backplane interconnects. We present longest matching prefix techniques which help solving the other three factors. They allow for a high rate of forwarding decisions, quick updates, and can be extended to classify packets based on multiple fields.
The best known longest matching prefix solutions require memory accesses proportional to the length of the addresses. Our new algorithm uses binary search on hash tables organized by prefix lengths and scales very well as address and routing table sizes increase: independent of the table size, it requires a worst case time of log_{2}(\textit{address bits\textit{) hash lookups. Thus only 5 hash lookups are needed for the current Internet protocol version 4 (IPv4) with 32 address bits and 7 for the upcoming IPv6 with 128 address bits. We also introduce \emph{mutating binary search} and other optimizations that, operating on the largest available databases, reduce the worst case to 4 hashes and allow the majority of addresses to be found with at most 2 hashes. We expect similar improvements to hold for IPv6.
We extend these results to find the best match for a tuple of multiple fields of the packet's header, as required for QoS support. We also show the versatility of the resulting algorithms by using it for such diverse applications as geographical information systems, memory management, garbage collection, persistent object-oriented databases, keeping distributed databases synchronized, and performing web-server access control.},
keywords = {Fast Routers, Hash Tables},
pubstate = {published},
tppubtype = {book}
}






