

Drew Austin raises an important question in Wired: How should we deal with our accumulated personal data? How can we get from randomly hoarding to selection and preservation? And why does his proposed solution of Web3 not work out? A few analytical thoughts.
More thoughts on blockchain and Web3 can be found here.
Current situation
We as individuals, organizations, and the entire society as a whole are creating increasing amounts of data. But then are stuck what to do with them.
Look at your email workflow: What do you do after processing your emails in your inbox? Delete them? Archive them? How long?
How about your photo collection? Will you ever look at it again? How do you find that impromptu family picture, taken some five or six years ago, where your brother looked so cute?
Some organizations have institutionalized this, but how do we, as individuals, handle this?
Structuring the problem
Archivists have collected best practices for this over the centuries. A typical workflow includes:
- Acquisition: Obtaining the material
- Arrangement: Structure the material into categories or topics
- Selection: Chose what you want to keep (and maybe decide, how long)
- Annotation: Add cataloging metadata, describing the material, so it can easily be found again
- Preservation: Ensure that the data will not deteriorate and can still be accessed/read later (think decades or centuries!)
This workflow includes subject matter experts, archivists and conservators, to name just some of the jobs and skills involved. If it is being done by trained personnel on time allocated for that purpose (and, typically, also paid), the process has been shown to work well for physical objects over centuries. Variations of this process are in use for digital data, still being fine-tuned.
But this requires time and money, and also commitment. How can this be ensured for individuals or small organizations without the resources?
1. Acquisition
For individuals, this is typically trivial: You already have the data. Also, for small organizations, this might be simple to achieve.
2. Arrangement
Grouping is somewhat more complex, but assuming we later have enough metadata and search, this step might be skipped.
3. Selection
Individuals creating large amounts of data is a new phenomenon. Previously, selection was left to experts (scholars citing, librarians curating, bookkeepers/engineers classifying, …). The goal and its value to society/the company were clear.
As individuals, we need to learn how to do perform selection on our own data. Few of us are willing to spend time on it, even though it might help you organize both your data and thoughts.
For some things, it might be dear (or important) enough to do it manually. For other parts, it might be helpful to use automated tools; e.g., train some AI based on your preferences and accept that some decisions might go wrong.
4. Annotation
In a first approximation, annotation can also be simplified: We have full-text search for text, which will definitely improve over time. For images, we have classifiers as well. Both have their drawbacks, but hey, you can’t have the cake and eat it.
5. Preservation
Again, as a society/organization/individual, we need to state how much we value preservation.
Archivists have been doing that for physical representations, typically being paid for their jobs. For digital data, libraries and online archives have started archiving as part of their overall duty and budget.
This does not scale yet to individuals or organizations. Yes, we need a general, simple solution. However, I shudder when reading in the article that Web3 will solve the problem. When monetary incentives from the underlying business model (“line goes up”) ever dwindle, so will the number of replicas maintaining a copy.
And it is not that the overall Blockchain ecosystem needs to die, before your data becomes extinct. It suffices for your particular chosen Blockchain project to die, the one your data is on. And how would you know that one of those hundreds of blockchains currently out there will survive for decades or even centuries?
Just remember that 15 years ago, before the dawn of the iPhone, we did not think that just a few years later everyone would be able to take pictures even in remote areas and share them with the world in just a few seconds. Or that we could obtain a local map, an encyclopedia entry, or a restaurant reservation while being far away from home.
Also, having an entire Blockchain as your archival unit, you lose the ability for selection, which is what the article started out with. Retaining everything forever cannot be the goal.
And you having to retain everyone else’s data just to keep yours may also not be your first choice, especially as that data may be millions or billions times larger than your own data. Having smaller, more flexible collections is probably the way to go (and git repositories could be such an idea, supported by several web publishing systems).
Whatever you chose: Make sure there is an incentive, monetary or otherwise, to keep that data. And commitment from your side as well.
Some 20 years ago, many ideas were floating around: Tit-for-tat, LOCKSS, … in addition to monetary ones. We should reconsider them.
Thinking clearly about the goals we want to achieve and how to achieve them is more important than just randomly stating buzzwords. Because Web3 is just expensive P2P.
Acknowledgements
This article was prompted by a post by Matthias Bürcher and incorporates some of his feedback. Thank you!
The article’s teaser image was rendered by DALL•E 2 using the prompt “A heap of data. Steampunk style.” and extended/modified using generation frame and eraser. Plus some final touches by me (moving the orange ink bottle into the selection; otherwise, that area would have resembled sky instead of something more table-ish).
Blockchain ecosystem
More posts in the blockchain ecosystem here, with the latest here:
- The year in review
 This is the time to catch up on what you missed during the year. For some, it is meeting the family. For others, doing snowsports.… Read more: The year in review
This is the time to catch up on what you missed during the year. For some, it is meeting the family. For others, doing snowsports.… Read more: The year in review - NFTs are unethical
 As an avid reader, you know my arguments that neither NFT nor smart contracts live up to their promises, and that the blockchain underneath is… Read more: NFTs are unethical
As an avid reader, you know my arguments that neither NFT nor smart contracts live up to their promises, and that the blockchain underneath is… Read more: NFTs are unethical - Inefficiency is bliss (sometimes)
 Bureaucracy and inefficiency are frowned upon, often rightly so. But they also have their good sides: Properly applied, they ensure reliability and legal certainty. Blockchain… Read more: Inefficiency is bliss (sometimes)
Bureaucracy and inefficiency are frowned upon, often rightly so. But they also have their good sides: Properly applied, they ensure reliability and legal certainty. Blockchain… Read more: Inefficiency is bliss (sometimes) - The FTX crypto exchange and its spider web
 Yesterday, the U.S. Securities and Exchange Commission (SEC) released its indictment against Sam Bankman-Fried. It details the financial entanglements of FTX, Alameda Research and more… Read more: The FTX crypto exchange and its spider web
Yesterday, the U.S. Securities and Exchange Commission (SEC) released its indictment against Sam Bankman-Fried. It details the financial entanglements of FTX, Alameda Research and more… Read more: The FTX crypto exchange and its spider web - Web3 for data preservation? (Or is it just another expensive P2P?)
 Drew Austin raises an important question in Wired: How should we deal with our accumulated personal data? How can we get from randomly hoarding to… Read more: Web3 for data preservation? (Or is it just another expensive P2P?)
Drew Austin raises an important question in Wired: How should we deal with our accumulated personal data? How can we get from randomly hoarding to… Read more: Web3 for data preservation? (Or is it just another expensive P2P?) - Rejuvenation for Pro Senectute through NFT and Metaverse?
 Pro Senectute beider Basel, a foundation to help the elderly around Basel, launched its NFT project last week and already informed about its Metaverse commitment… Read more: Rejuvenation for Pro Senectute through NFT and Metaverse?
Pro Senectute beider Basel, a foundation to help the elderly around Basel, launched its NFT project last week and already informed about its Metaverse commitment… Read more: Rejuvenation for Pro Senectute through NFT and Metaverse? - What is an NFT, behind the scenes?
 “NFT” is currently on everyone’s lips again, and not only because of Pro Senectute. But what is actually behind the full-bodied promises of the NFT… Read more: What is an NFT, behind the scenes?
“NFT” is currently on everyone’s lips again, and not only because of Pro Senectute. But what is actually behind the full-bodied promises of the NFT… Read more: What is an NFT, behind the scenes? - Offline digital cash?
 The question of using digital money in the event of a network outage comes up again and again. Here is an overview of the options… Read more: Offline digital cash?
The question of using digital money in the event of a network outage comes up again and again. Here is an overview of the options… Read more: Offline digital cash? - The NFT Danger Zone
 Susanna Petrin closes her NFT experiment with a dystopia of life after we destroyed our environment: Admiring our NFTs while strolling through the metaverse. I… Read more: The NFT Danger Zone
Susanna Petrin closes her NFT experiment with a dystopia of life after we destroyed our environment: Admiring our NFTs while strolling through the metaverse. I… Read more: The NFT Danger Zone - A business-driven blockchain evaluation flow chart
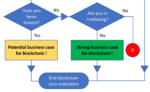 Yesterday, Rene Jan Veldwijk posted a blockchain decision flowchart he had previously used in a presentation.
Yesterday, Rene Jan Veldwijk posted a blockchain decision flowchart he had previously used in a presentation. - Blockchain in a nutshell
 People often try to claim blockchain use cases without much deliberation. Here is a condensed, quotable version of «Hitchhiker’s Guide to the Blockchain» and «Data… Read more: Blockchain in a nutshell
People often try to claim blockchain use cases without much deliberation. Here is a condensed, quotable version of «Hitchhiker’s Guide to the Blockchain» and «Data… Read more: Blockchain in a nutshell - Web3 is just expensive P2P
 Web3 claims to be the only way to save us from commercial entities defining what we can see and what not. Yet, it does exactly… Read more: Web3 is just expensive P2P
Web3 claims to be the only way to save us from commercial entities defining what we can see and what not. Yet, it does exactly… Read more: Web3 is just expensive P2P - Git, PGP, and the Blockchain: A Comparison
 The Blockchain, a cryptographically linked list with additional restrictions, is often touted to be the most significant innovation towards democratization of the digital landscape, especially… Read more: Git, PGP, and the Blockchain: A Comparison
The Blockchain, a cryptographically linked list with additional restrictions, is often touted to be the most significant innovation towards democratization of the digital landscape, especially… Read more: Git, PGP, and the Blockchain: A Comparison






