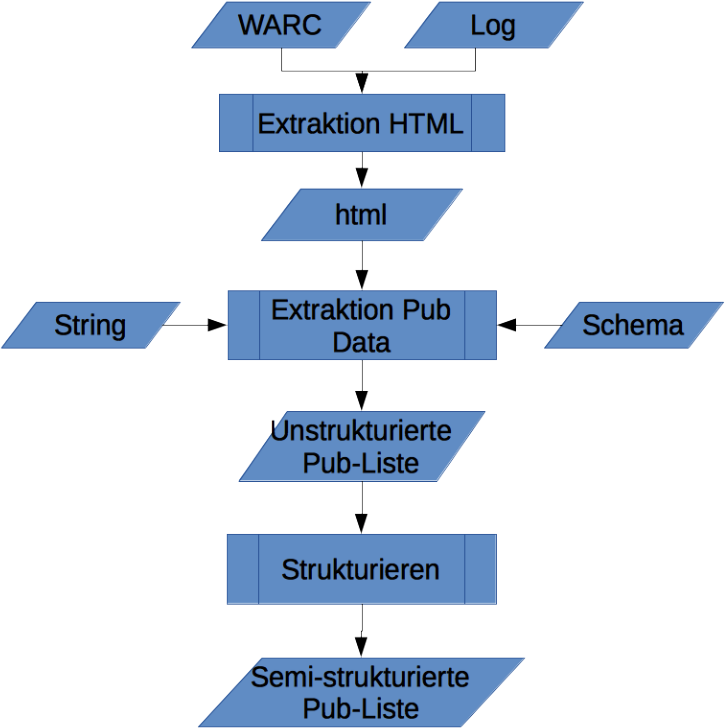
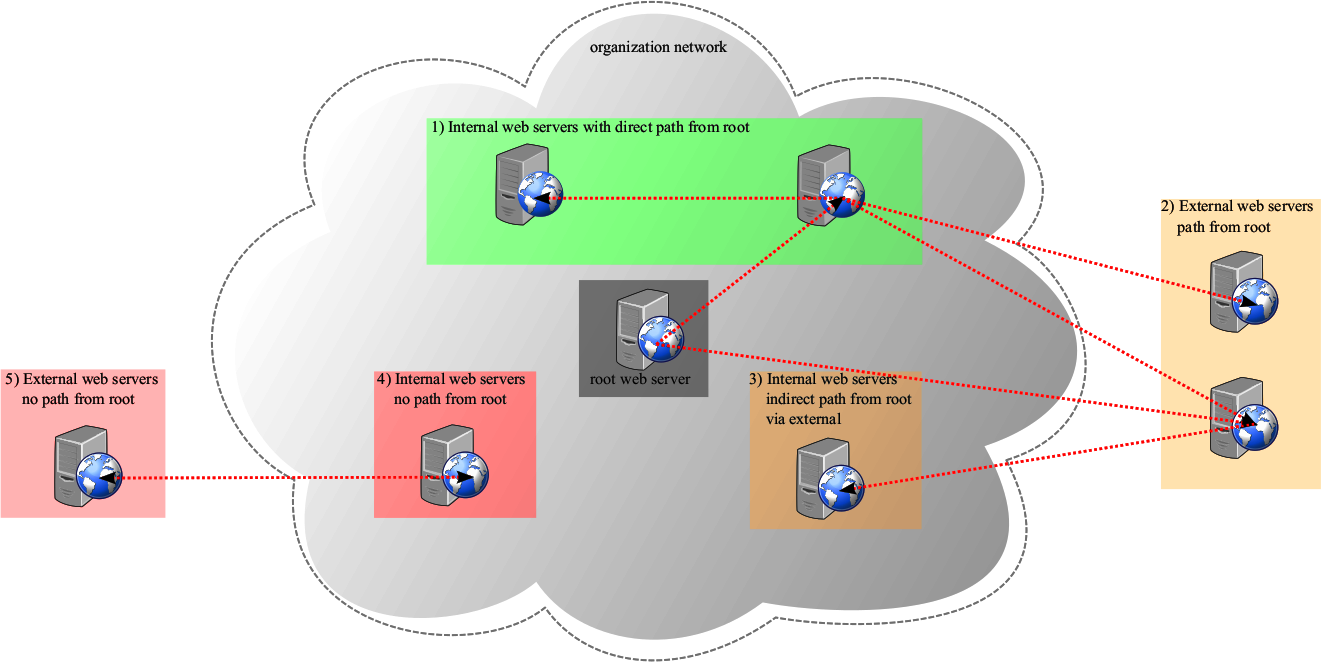
Drew Austin raises an important question in Wired: How should we deal with our accumulated personal data? How can we get from randomly hoarding to selection and preservation? And why does his proposed solution of Web3 not work out? A few analytical thoughts.