

Good news is that NTS relies on DNS names, no longer “naked” IP addresses. But what happens when the DNS name changes, pointing to a different IP address? A look at the protocol, the Chrony source, and the implications.
(This is part 3 in the NTS series. Did you already read part 1?)
The NTS protocol: RFC 8915
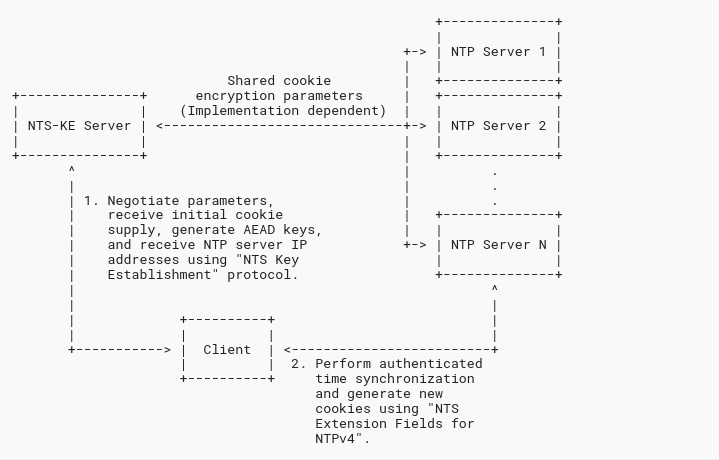
RFC8915 starts with a protocol overview in their Figure 1, republished here. From the address resolution perspective, the following happens:
- The NTS client obtains the IP address(es) of the NTS-KE (Key Establishment) service through a DNS lookup of the name specified in the
serverstatement of the configuration file. - The client connects to the NTS-KE server over TCP, typically to port 4460 and performs a TLS handshake. The NTS-KE will return a list of 8 security cookies and the cryptographic parameters. (Optionally, the actual IP address or host name of the NTP server(s) can be returned, if an address other than the one of the NTS-KE server should be used.)
- The client then talks to this IP address, verifying the authenticity of the peer using those cookies.
So, the main differences (besides the security aspects) are:
- There is now always a DNS name (FQDN) involved, as this is also used to authenticate the TLS session. Some legacy NTP setups still preferred IP addresses, as this made NTP independent of DNS. (Setups without FQDN are theoretically possible, but at the cost of losing most security benefits of NTS.)
- The NTS-KE server could return a different IP address for the actual NTP handshake. It seems that this protocol feature is not currently used (and neither Chrony nor NTPsec currently support it).
So, in theory, NTS should work with NTS servers behind dynamic IP addresses.
Cookie refresh
After this initial, rather expensive, NTS-KE phase, the NTP protocol should continue almost as efficiently as before. Therefore, on each NTP exchange, one cookie is used and the cookie pool requested to be refilled in a single (longer) NTP message.
Normally, this means one cookie is used and it is directly refilled. However, if a request is not answered (packet lost, server down/unreachable, …), more than one cookie needs to be returned, to get back to 8 spares.
The Chrony source
When no cookies are available, either because the client just started up or because the last 8 NTP packets went unanswered, the get_cookies() function is called to replenish them. This again starts with the DNS lookup as explained above. So, a DNS lookup is performed again, which hopefully returns the new address for the NTS-KE server and everyone gets happy again.
I presume that NTPsec behaves similarly; at least, that’s what is supposed to happen.
Being client to a dynamic NTS server
So, what happens, when a server you talk to changes IP address?
First, the NTP client will continue and try to talk to the server at the old IP address. However, there will be no response at all, or, if the new machine behind that address also talks NTP and/or NTS, the answers will not be correct, as the authentication of the NTP packets will not succeed.
After eight such attempts, all cookies will have been used up, causing a protocol restart to replenish the cookie jar.
How long for recovery?
With the default value of maxpoll 10, after some initialization time, the server will be polled every 210=1024 seconds, resulting in the cookie storage being expended after around 8192 seconds or roughly 2¼ hours. If the DNS record has expired by then (which it should, if you expect the address to change periodically), the NTS-KE phase will succeed immediately and time synchronisation resume after roughly 136 minutes. If the local clock is running reasonably stable or other NTP/NTS sources are configured, this should go unnoticed by the rest of the system.
However, if the old DNS record has not been updated or is still cached, for example, after an unexpected change or downtime, further delays can be introduced. Here the parameters from the Chrony source:
- If the NTS-KE connection attempt fails, it is being retried with exponential backoff starting at 24=16 seconds, with a limit at 217=131072 seconds, roughly 1½ days.
- If the NTS-KE connection succeeds, but TLS fails, the same exponential backoff is initiated, but starting at 210=1024 seconds already.
Updated 2022-01-12: The standard says that clients SHOULD start with at least 10 seconds and increase by a factor of 1.5 after every failure, up to a maximum retry interval of 5 days.
So, if your NTS server changes its IP address without timely updating DNS, after about a day or so, clients will only retry connecting to your server every 1½ days, if the client is Chrony. The same happens when your server is misconfigured or serves an expired certificate. [Updated 2022-01-12:] Expect that some clients might even retry only every 5 days, so really try to avoid this situation.
Operating a dynamic TLS server
First of all, any NTP server should aim for stable IP addresses. Sometimes, however, you have no choice. And if the IP address changes only every blue moon or so, the 2 hour outage seen by clients will likely not be a problem.
But you should take care that your DNS record is updated in time, i.e., the latency before the update plus the DNS TTL should sum to at most 2 hours, less, if you have clients with smaller maxpoll.
About 2 hours after the IP address change, the server will receive an NTS-KE request from each of its NTS clients. It should be prepared to handle this additional load.
Also, rate limits should take this into account. The Chrony rate limits are off by default and are per IP address. The default after enabling NTS rate limits is to only accept 1 NTS-KE request every 64 seconds. This will not be enough if you have many NTS clients behind a single NAT/CGNAT address, so you will have to increase the burst value.
Independent of whether you operate a server behind a dynamic or static IP address, you should also take care that your server always responds to port 4460 queries and with the correct certificate. Otherwise, clients are quick to only retry NTS-KE connection every 1½ to 5 days.
Additional addresses
Something similar happens if you add additional addresses to your server, for example an IPv6 address, after you started IPv4 only. Unless your legacy address becomes unavailable for a few hours or clients restart, they will not pick up the additional address.
(Changing addresses/protocols often is not desirable, BTW, as this may lead to additional jitter. For example, the NTP Pool monitors see delays between the same pair of machines differ by 5 ms and more, just because of different routes or queueing configuration by the transit ISPs.) https://www.ntppool.org/a/trifence






