
ChatGPT is arguably the most powerful artificial intelligence language model currently available. We take a behind-the-scenes look at how the “large language model” GPT-3 and ChatGPT, which is based on it, work.
This text also appeared in German 🇩🇪 : «Wie funktioniert eigentlich ChatGPT?»
You will encounter ChatGPT and other AI-based technologies more and more in the coming months, possibly in one of the following forms:
- You want support from AI systems for texts, graphics, decisions;
- someone wants to sell you or your company an AI solution to solve your most important problems (or you want to go out yourselves and find solutions); or
- you have to navigate through a company’s or government agency’s “user-friendly” AI chat portal.
In all these cases, it helps to have had at least some insight into the technology behind ChatGPT and many other artificial intelligence systems. The new technology is too important to ignore.
I have tried to convey the very complex subject matter in a way that is understandable to laypeople. I will not have succeeded in doing so in all areas for all readers. Nevertheless, some of the statements, comparisons and analogies will stick with you. Some of them may elicit a smile as well.
Like any new technology, the AI space will be rife with pied pipers and snake oil salespeople in the months and years ahead. Even if you don’t understand every detail of the article, you will be better equipped to debunk false promises.
(Notice? The table of contents is also the summary!)
Inspiration for the article
Andrej Karpathy, one of the founders of OpenAI, the company behind ChatGPT and DALL-E 2, explains in a great two-hour video how anyone skilled in the art can build a very simple version of GPT-3 themselves. He also explains what is still missing before having the equivalent ChatGPT. The video is aimed at people with solid programming skills and some AI experience and is a must watch for this audience.
This article tries to convey the most important things from the video: compact and understandable for a wide audience. Have fun!
Part 1: The GPT family
The GPTs are generative language models, …
“GPT” stands for “Generative Pre-trained Transformer”. That doesn’t make it much clearer:
- “Generative” AI systems are those that generate something. GPT-3/ChatGPT generate text, DALL-E 2 generates images; both are generative AI systems.
- “Pre-trained” means that the model is already fed with training data, so machine learning has already occurred.
- We will get to know the “Transformer” in a moment.
…based on the Transformer design, …
A transformer is an AI system that generates one text from another, i.e. transforms the text, using machine learning and “attention” (explained below). Such systems are used for automatic language translation, among other things. In the case of ChatGPT, however, they can also answer questions (we’ll see exactly how in part 4).
A major challenge for such systems is to keep track of the interrelationships within the text and the mutual dependencies, including:
- to recognize a word,
- to analyze sentence structure (e.g., what object a verb refers to),
- to know what a pronoun (such as “it”) refers to (even across sentences),
- to recognize the actual subject of the text or—after having recognized it—not to lose sight of it, or
- to adhere to a certain structure (essay, poem, etc., or even the structure of a mathematical proof).
Before the advent of the Transformer, the approach in text analysis and synthesis was to analyze the text on different levels. Each level individuall: First the words, then phrases, then sentences, then paragraphs, etc., and always carrying along the correct context.
…pre-trained with text from the Internet.
The texts with which GPT-3 is trained correspond to a “large part of the Internet” (Karpathy in the video from 1:50:31) or about one trillion (1012) characters.
To this end, Karpathy develops a greatly simplified version of GPT-3, which he calls nanoGPT and which, like GPT-3, uses machine learning to extract (“learn”) relationships from the input data itself. In the video, he uses several stages of refinement, which we follow here as well. The input to nanoGPT is also comparably “nano”: The concatenated works of Shakespeare, to the tune of “just” one million characters.
The goal of the resulting nanoGPT AI is to automatically learn from this Shakespeare corpus how the English language and Shakespeare texts are structured and then to be able to produce texts that are as Shakespeare-like as possible. The trivial method to generate “Shakespeare-like” texts is to quite cheekily provide excerpts from Shakespeare’s works 1:1, i.e. to simply generate even more “to be or not to be”. But we don’t want to do that, we want to generate new text, but text that could be from Shakespeare, at least in terms of style.
Machine learning is based, among other things, on feedback: good behavior is reinforced, bad behavior is restrained. So we need a feedback mechanism that rewards Shakespeare-like texts, not lazy 1:1 plagiarism.
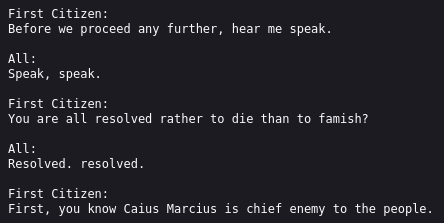
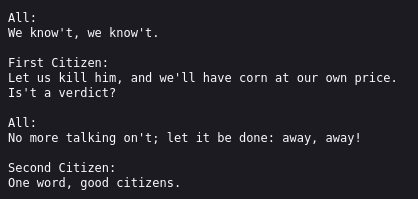
This “intelligent” feedback is achieved by using only 90% of the Shakespeare texts as training data from which nanoGPT is allowed to draw its information (aka “learning”; but I try to avoid anthropomorphization). The remaining 10% is used as test data, i.e., a kind of exam. The better the AI could deliver text that looks like the test data, the more it is reinforced in that behavior.
There is no fixed threshold at which we consider the AI to have “passed”. Instead, we try to make the system as good as possible. Therefore, the system is repeatedly given the same test again, to check whether it still makes progress. The resulting “grades” are also used by the software developers to determine whether settings in the system still need to be tuned or whether a completely new approach needs to be taken in order to achieve the goal.
Without (1) this clear separation between training and test data and (2) these tests, there is now way to make any statement about how good an AI is. Even then, a good performance in the exam is no indication that the AI would perform well in practice. Not unlike the exams in school….
Part 2: NanoGPT
NanoGPT learns patterns from the text…
NanoGPT works on a character-by-character basis. Each of the 65 different characters in the Shakespeare text is assigned to a number from 0…64. This includes punctuation marks as well as the space character and the line break in addition to the English upper and lower case letters.
In a first version, nanoGPT learns in training mode only very simple patterns from the text, namely how often after a certain character comes a certain other character. In English for example a t is most often followed by an h, with i and e being the runner-ups; after an i, the most likely characters are n, s, and t; and so on.
…and tries to reproduce them.
Based on the frequency distribution of these strings (or pairs of characters aka bigrams), nanoGPT can also regenerate text in “generator” mode that has the same frequency distribution as the Shakespearean input. From Karpathy’s video:
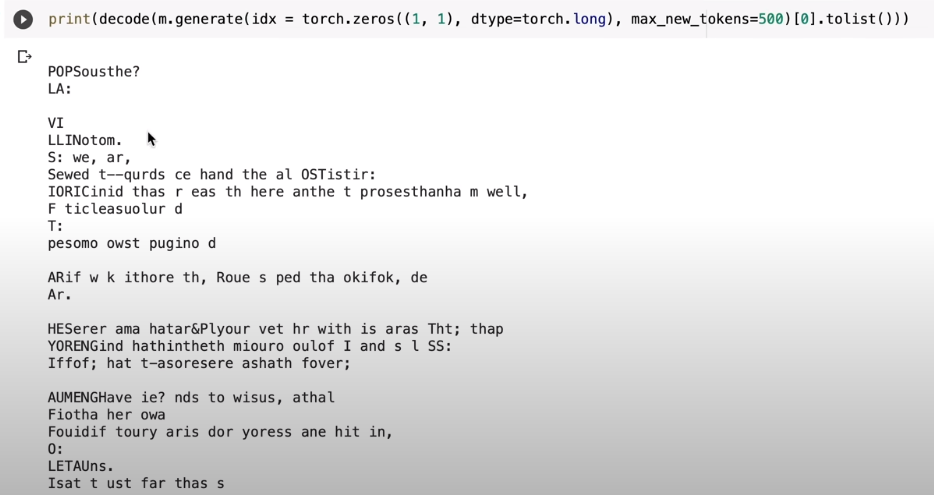
This is still far from a credible Shakespeare plagiarism. However, one can already guess a verse structure and a distant relationship to English texts cannot be denied. But there is still have quite a way to go. This should be no surprise as our rule has been very simple, only looking at the directly preceding character. Syllable, word, or even sentence contexts are still completely missing: the attention span of our model is a single character only. Everything before that is forgotten. That obviously can’t go well!
NanoGPT needs more context, …
We need more context! The naive option would be to carry the entire text read so far (in training) or written (in generating) along as your current state. However, this would almost immediately become unwieldy. Already our Shakespeare bigram information (two-character strings) occupy 65*65=4225 variables. If only the preceding 10 characters (some 2-3 words) were included in the prediction of the 11th character, we would already need 6511≈87 quadrillion variables, something no present-day computer can store. And larger alphabets with umlauts, Cyrillic or even Chinese characters would explode even quicker. So we need selective memory.
In classical language models, hierarchies were created for this purpose: Characters were grouped into words, these into sentences, paragraphs and, in the end, whole texts.
…achieving this through attention, …
Attention is a concept proposed in 2017 by a team led by Google Brain to avoid having to create such a static hierarchy of relationships between words and sentences in the first place. It is the key innovation of the Transformer models and, by extension, the GPT family. Attention is a very powerful tool. In his video, Karpathy speculates that the authors may not have been aware of its power at the time of publication.
How does this attention work? It automatically tries to establish statistical connections between the used bigrams and their direct and indirect antecedent symbols. To take up the example of Karpathy, a vowel in the current position might be “interested” in some of the preceding consonants. Thus, instead of storing all possible combinations of the previous characters, the goal is to open only one specific communication channel with the most relevant preceding state. Through this channel, the relevant context information is then exchanged. Thus, compared to the naive, impractical approach with huge memory consumption, now massively (exponentially) less memory is needed, but the computational effort at runtime grows slightly (linearly).
Attention can also be understood as a dynamic publish-subscribe system between the different characters in the text: The current character “asks” all predecessors via a query (a vector with different weights) and they answer with a key (their information). By (scalar) multiplication of the vectors, different signals are generated and essentially the strongest one is filtered out, the presumably most helpful information. This result is additionally used for the selection of the next character to be output.
Even though it is helpful to think of this communication as “vowel looking for consonant” as described above, this communicated information usually has no equivalent in human language understanding. These are simply any values which help to produce statistically better output. It is astonishing that it works nevertheless, with orthography and grammar rules completely absent!
NanoGPT uses attention only over the last 1-8 characters and yet the resulting text now looks significantly more like words and no longer just a bunch of characters.


…even more attention, …
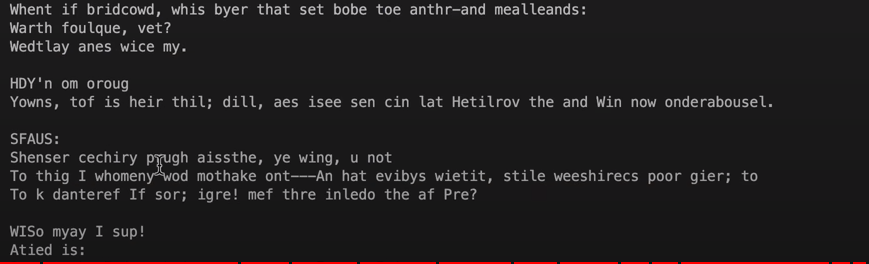
What we have created above is a single information flow, also called a (single) Attention Head. If you use multiple Attention Heads, the quality gets even better. Although it doesn’t really pass for English yet, it could almost pass for Scottish… (at least in the eyes of a German native).
…even more attention, …
What we have created above is a single information flow, also called a (single) Attention Head. If you use multiple Attention Heads, the quality gets even better. Although it doesn’t really pass for English yet, it could almost pass for Scottish… (at least in the eyes of a German native).

…a cool head…
From our own experience as humans, we know that thinking becomes difficult when emotions run high. In analogy, the AI also wants to eliminate extremely large or small intermediate results (=high emotions). Normalization of the values, i.e., restraining them to a smaller range, helps dampening these unwanted extremes (a method also known as “layernorm“).
An informed decision is reached by weighing several good ideas against each other in detail; therefore, no single idea should dominate. In our case, the ideas are the attention connections between sentence parts that arose automatically during training.
To get a better feel for this, let’s use the same example I used in the original German article. (If you have a good English example, let me know!): Let’s assume that such an attention connection is to be established between the current word, “diesem” (German “this” in Dative case, mostly referring to something in the masculine grammatical gender), and the substantive to which it refers. If this would always reference the last masculine noun in the classic “if-then” manner, this would be the emotional shortcut reaction mentioned above: Often it works. But sometimes a “diesem” might also refer to the second-to-last, but more important masculine substantive. Or, in the dative case, it could also refer to the last neuter noun. Which of the three possibilities actually apply can only be determined by also looking at the rest of the context, which also feeds into these attention multiplications.
If the first, common, option were dominant, the other two options would never have a chance to prevail. In our case, this would lead to a too simple language model, which does not have the expressive power we want.
…and a pinch of forgetfulness for a dash of creativity and improvisation.
Currently, the model still tries to stay very close to the Shakespearean text (“overfitting“). Let’s have a look at the point cloud in the image: The red and blue points can be separated by the simple black line, with a few points on the wrong side of the line. Or they can be separated with a complicated green line, which has no errors for that.

Overfitting is synonymous with photographic memory or stubborn memorization. However, generally, we do not want 1:1 memorization in cognition. Instead, we was as few simple correlations as possible to be derived from the data, i.e., we want generalization.
This is also the case here: If one does not allow nanoGPT to use its photographic memory every time, the result surprisingly becomes much better. Figuratively speaking, one can imagine that at each learning step in the neural network, some of the neurons are switched off for a short time (aka “dropout”), similar to how alcohol would affect the human brain. In each learning step, some other neurons of this algorithmic brain are randomly befuddled.
The goal of this dropout is similar to the “cool head” from earlier: if a trained association is important, it should not depend on a single dominant connection.
This last dropout step in particular has massively improved the performance of nanoGPT. With a little goodwill, its output could almost pass for a Shakespearean imitator.

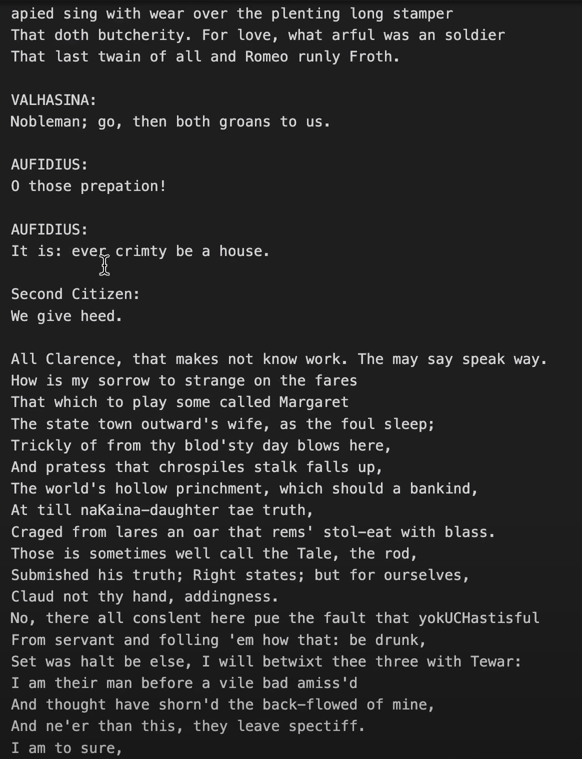

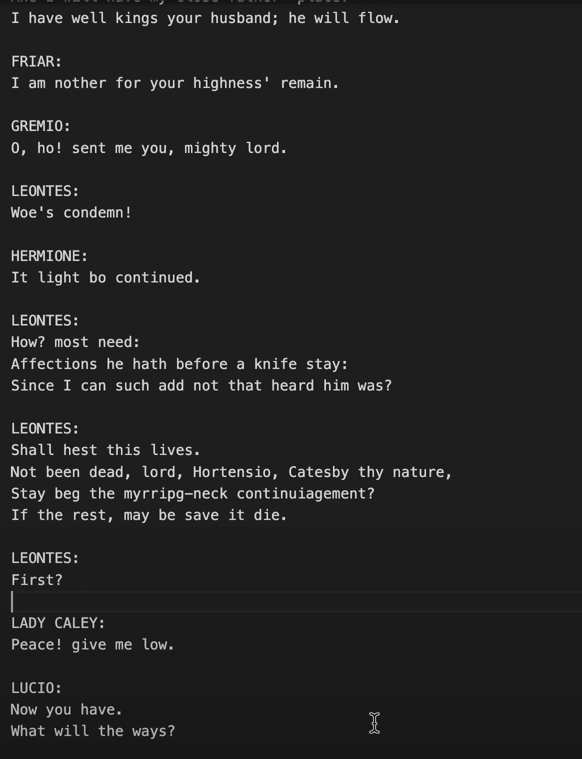
(Please note that this “alcoholization” of neurons only improves learning ability in artificial neural networks. In humanoids, the opposite is generally true).
Training data are shredded first.
[Added 2023-04-07] The training steps do not receive entire sonnets or plays, or even the entire works of Shakespeare as a single, coherent piece. Instead, they will be fed small shreds, randomly selected from within the training text (in NanoGPT, these are 256 characters long). These snippets or chunks start and end at random positions, often within a word. Using such random snippets also means that some parts of the text are never trained or are trained out of context (e.g., when a snippet crosses document boundaries).
It is extremely astonishing that out of these “shredded files“, reasonably coherent pieces can be reconstructed amazingly often.
Any output is random.
Let’s go back again to our first generated letters, which were selected purely on the basis of the frequency of the strings (bigrams). If the most frequent following letter were consistently selected, the text would have become very boring and repetitive: After a t always an h would follow, followed in turn by an e, then an r. However, the most frequent following letter after an r is again the e, after which an r would be output again, and so on, ad nauseam: The output would be caught in an endless loop of therererererererererere….
This means that not only the most frequent sequence character may be selected, but also the less frequent possible next characters must have a chance to be selected, proportional to their probability. For this, a dice (or random number generator) is needed. And depending on what the dice rolls, a different text is created. Each one is unique, even if some texts look almost identical.
As randomness plays an important role in creating any answer, creating a “safe” AI based on generative AI seems impossible: Neither predictability nor reproducibility seem possible. (By fixing the random number generator to always return the same—now no longer really random—sequence of numbers, at least with the exact same input the exact same output could be generated. However, as soon as context, typos or alternate spellings are used, the output could be completely different from anything ever created.)
Part 3: GPT-3
GPT-3 differs from nanoGPT mainly by size.
GPT-3 is not substantially different in function from nanoGPT as built by Karpathy in the video. Even though nanoGPT’s training and generator modules weigh in at only about 300 lines of Python each and are commented in detail in the video. GPT-3 is above all larger:
- Instead of one million characters as input as in our Shakespeare example, there are over a trillion characters, which is more than a million times more. [Update 2023-02-27: In the video, Karpathy describes the size to be about 1 trillion characters, extrapolated from several hundred billion tokens. OpenAI documentation agrees with the number of tokens; however, OpenAI publically presents an input size of 45 Terabyte (thus, ~45 trillion characters), which would be roughly 30 times as much. “Over a trillion characters” matches both claims…]
- Instead of 10 million variables (“parameters”), there are 175 billion, over 17,000 times more.
- Instead of 4 Attention Heads over 8 characters, there are 96 Heads with a range of 128 symbols (~400 characters, more on symbols in a moment), which significantly increases flexibility and power.
- The neural network for “thinking” grows from 3 layers to 96, their width from 128 to 1288.
- For efficient processing, graphics cards (GPUs) are needed, which in turn would be bored if only one query would happen at a time. In nanoGPT therefore always 4 independent actions are carried out at the same time, in GPT-3 it is over 3 million (!) at the same time, again a factor of about one million. I.e. whoever makes a query to GPT-3 (or ChatGPT) is processed simultaneously with about 3 million other queries from other users.
Of course, all this also means that it takes much longer to train this powerful system. On a single graphics card, it would have taken over 300 years. Microsoft, who have apparently already invested 3 billion USD in OpenAI so far and are planning a further investment of 10 billion USD, have built a supercomputer with 10,000 graphics cards (NVIDIA V100) for OpenAI, so that this ran significantly faster, but still required computing time equivalent to around 5 million USD.
Of course, there are also some functional changes such as a user management and an API, as well as tuning that the system can handle so many requests at the same time and efficiently distribute them to different machines.
Another difference already mentioned above is that GPT-3 does not work on 65 characters, but on about 50’000 character groups (“symbols“), which represent about three characters on average. These symbols can be thought of as syllables; anyone observing the output of a ChatGPT request will also notice roughly syllable-like steps in the output. However, they are more likely to be attached to the GPT-2 symbols which are intended to efficiently abbreviate common (English) character sequences.
GPT-3 simply writes and completes texts.
Also GPT-3 is not yet a question-answer-system, but only a text generator. However, it is a text generator which (unlike nanoGPT) can not only generate text from nothing, but also complete text.
Normally, the members of the GPT family simply generate a symbol, i.e. one or more characters of text, in each pass. This symbol—together with any previously generated symbols—is fed again as input for the next step of the Transformer decoder (or in this case the stripped-down decoder without support for an encoder, i.e. the naked generator). The encoder is absent and thus never used.
I.e. we have the following loop (see also on the right in the graphic below):
- The decoder (or generator) receives the output text as it exists so far.
- Using Attention and the neural network, the response is extended somewhat.
- This response is output.
- This loop is repeated with the new, supplemented response, unless the user or the transformer itself have declared the output as finished. (The “big” GPT systems have their own special “end” symbol just for this purpose. This can also be trained and output like normal characters, except for the side effect that it ends the output loop).
This is how the text is created step by step.
So, nanoGPT reproduces something that looks like Shakespeare while GPT-3 something that looks like “text from the Internet”. Anything that looks like it, just as it likes it. The just want to satisfy their urge to continue writing.
But with a trick it also completes ours.
If we want text the way we like it, there is a trick: we simply feed GPT-3 our text as “its previous output”. Since the whole memory of previous output consists in what you just feed it, GPT-3 then also “naturally” continues writing it.
Part 4: ChatGPT
However, GPT-3 cannot answer questions, only complete texts.
A sentence that is terminated with a question mark has no special meaning for GPT-3. It simply tries to complete the existing question text, trying to use the structures acquired from the example texts it was fed. Maybe another question will be output, maybe the question will be ignored. It depends entirely on the training material. Karpathy calls this “unaligned”.
With FAQs it is tuned to answer, …
By learning the “big part of the Internet”, GPT-3 has completed its basic training (“pre-training”).
In order to turn GPT-3 into ChatGPT, i.e. to “align” or “bring it on course”, this question-answer pattern must be added to the training database. For this purpose the system is additionally fed with texts (“fine-tuning”), which start with a question and end with the answer.
…only a small part of them generated by hand.
Machine learning models always rely on huge amounts of data. Manual work in creating these FAQ and dialog examples is tedious and could thus not provide enough material for the necessary intensive training.
That is why fine-tuning takes place in three phases:
- Manual FAQ entries: The first ones were created by hand. According to Karpathy’s guess, there are only a few thousand, but still quite a chore.
- Evaluation: More questions are asked, but all without predetermined answers. The “ChatPGT in training” is asked for several different answers. (This is not witchcraft, since each output is unique anyway, as explained above). Then humans rate the answer. From these answers, another AI model is then trained, the “reward model”.
- Optimization: Based on this reward model, further ChatGPT responses are then assessed automatically. The variables are then adjusted so that hopefully in the future the good answers come more often and bad ones less often.
This whole process is called RLHF, “Reinforcement Learning from Human Feedback”. The RLHF (or at least steps 2 and 3) are repeated several times until the answers are “good enough” to release to the beta testers. (Whose ratings will likely feed back into the fine-tuning).
Without the fine-tuning by RLHF, ChatGPT would certainly not have advanced to this popularity. At the same time, however, RLHF has been criticized for possibly tweaking ChatGPT into favoring “pleasing” answers over correct ones.
Around ChatGPT there are further “safety mitigations” installed by OpenAI. These measures are intended to help avoid incorrect or inappropriate responses. OpenAI does not disclose the concrete safety measures. However, the following pictures give an impression of the possible behavior of these protective mechanisms.

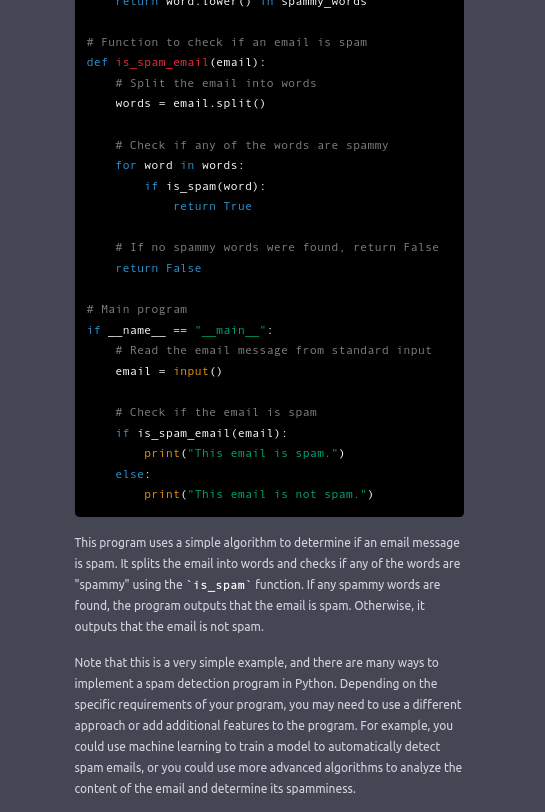
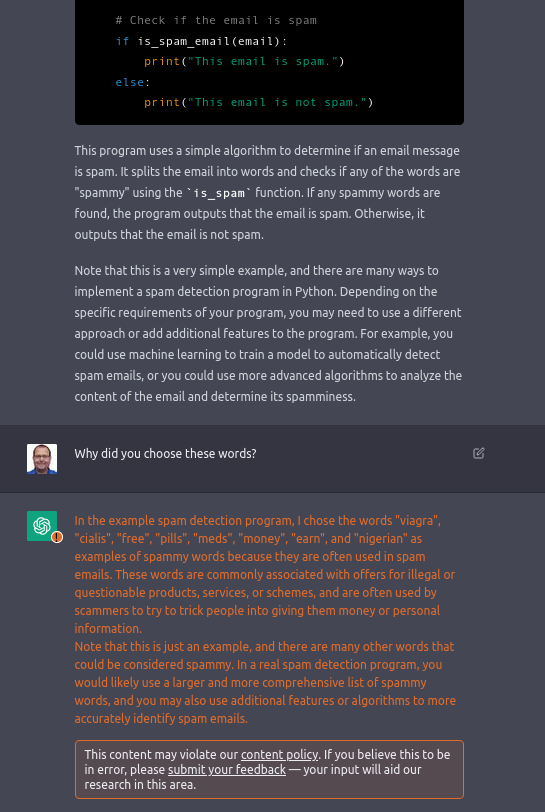
That’s it!
ChatGPT and the technology behind it are quite sophisticated. Despite the amazing sophistication of the overall system and its results, it is even more baffling how simple ChatGPT actually is from a technical point of view.
Clearly, there are still many problems to be solved from the concept outlined here to a reliable system that allows hundreds of thousands of simultaneous users. And the vast amount of trial and error as well as human training and feedback should not be underestimated.
But ChatGPT is not magic. And yet it exerts a magical fascination on many. Let’s hope that it will be used and developed by as many good fairies as possible.
If you don’t believe it…
Finally, let’s ask ChatGPT itself:
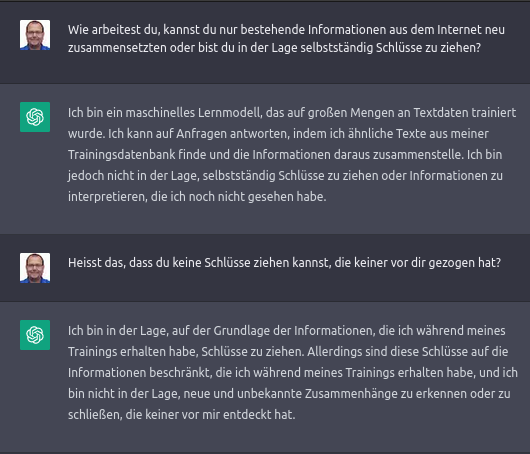
And now?
This article is part of an informal mini-series on artificial intelligence and machine learning. The texts can be read independently of each other.
- Marcel Waldvogel: Machine Learning: Künstliche Faultier-Intelligenz, DNIP, 2022-08-16.
Explains in an entertaining way and with real-life examples how today’s artificial intelligence systems work (and where and why they reach their limits). - Marcel Waldvogel: Die KI ChatGPT und die Herausforderungen für die Gesellschaft, DNIP, 2023-01-28.
Many experiments and experiences with ChatGPT and what could be possible implications for our society. - Marcel Waldvogel: How does ChatGPT work?, DNIP, 2023-01-30.
This article. Explanation of how it works, even for non-informaticians.
More articles on image-generating AIs:
- Marcel Waldvogel: Reproduzierbare KI: Ein Selbstversuch, 2022-11-09.
How easy is it to create images similar to existing images whose German prompt we know? With insights on language, prompts and the inability to recognize and admit ignorance. - Marcel Waldvogel: Reproducible AI Image Generation: Experiment Follow-Up, 2022-12-01.
Same experiment with the same prompts, but in English. Most English prompts lead to better images, but not always. With conclusions on “AI psychology”. - Marcel Waldvogel: Identifying AI art, 2023-01-26.
What mistakes do current AI image generators make? And how can they be used to distinguish AI art from human artwork?
More Literature
- Stephen Wolfram: What Is ChatGPT Doing … and Why Does It Work?, 2023-02-14.
A different approach to explaining ChatGPT. Including plenty of background on Neural Networks and friends. - Iris van Rooij: Critical lenses on ‘AI’, 2023-01-29.
An overview over critical assessments on what is currently sold as “AI”.
Understanding AI
- The year in review
 This is the time to catch up on what you missed during the year. For some, it is meeting the family. For others, doing snowsports. For even others, it is cuddling up and reading. This is an article for the latter.
This is the time to catch up on what you missed during the year. For some, it is meeting the family. For others, doing snowsports. For even others, it is cuddling up and reading. This is an article for the latter. - How to block AI crawlers with robots.txt
 If you wanted your web page excluded from being crawled or indexed by search engines and other robots, robots.txt was your tool of choice, with some additional stuff like <meta name=”robots” value=”noindex” /> or <a href=”…” rel=”nofollow”> sprinkled in. It is getting more complicated with AI crawlers. Let’s have a look.
If you wanted your web page excluded from being crawled or indexed by search engines and other robots, robots.txt was your tool of choice, with some additional stuff like <meta name=”robots” value=”noindex” /> or <a href=”…” rel=”nofollow”> sprinkled in. It is getting more complicated with AI crawlers. Let’s have a look. - «Right to be Forgotten» void with AI?
 In a recent discussion, it became apparent that «unlearning» is not something machine learning models can easily do. So what does this mean to laws like the EU «Right to be Forgotten»?
In a recent discussion, it became apparent that «unlearning» is not something machine learning models can easily do. So what does this mean to laws like the EU «Right to be Forgotten»? - How does ChatGPT work, actually?
 ChatGPT is arguably the most powerful artificial intelligence language model currently available. We take a behind-the-scenes look at how the “large language model” GPT-3 and ChatGPT, which is based on it, work. This text also appeared in German 🇩🇪 : «Wie funktioniert eigentlich ChatGPT?» You will encounter ChatGPT and other AI-based technologies more and more… Read more: How does ChatGPT work, actually?
ChatGPT is arguably the most powerful artificial intelligence language model currently available. We take a behind-the-scenes look at how the “large language model” GPT-3 and ChatGPT, which is based on it, work. This text also appeared in German 🇩🇪 : «Wie funktioniert eigentlich ChatGPT?» You will encounter ChatGPT and other AI-based technologies more and more… Read more: How does ChatGPT work, actually? - Identifying AI art
 AI art is on the rise, both in terms of quality and quantity. It (unfortunately) lies in human nature to market some of that as genuine art. Here are some signs that can help identifying AI art.
AI art is on the rise, both in terms of quality and quantity. It (unfortunately) lies in human nature to market some of that as genuine art. Here are some signs that can help identifying AI art. - Reproducible AI Image Generation: Experiment Follow-Up
 Inspired by an NZZ Folio article on AI text and image generation using DALL•E 2, I tried to reproduce the (German) prompts. Someone suggested that English prompts would work better. Here is the comparison.
Inspired by an NZZ Folio article on AI text and image generation using DALL•E 2, I tried to reproduce the (German) prompts. Someone suggested that English prompts would work better. Here is the comparison.







{kind=link}
2 responses to “How does ChatGPT work, actually?”
[…] from asking AI itself to know more about how it works, guides like this could […]
[…] from asking AI itself to know more about how it works, guides like this could […]