
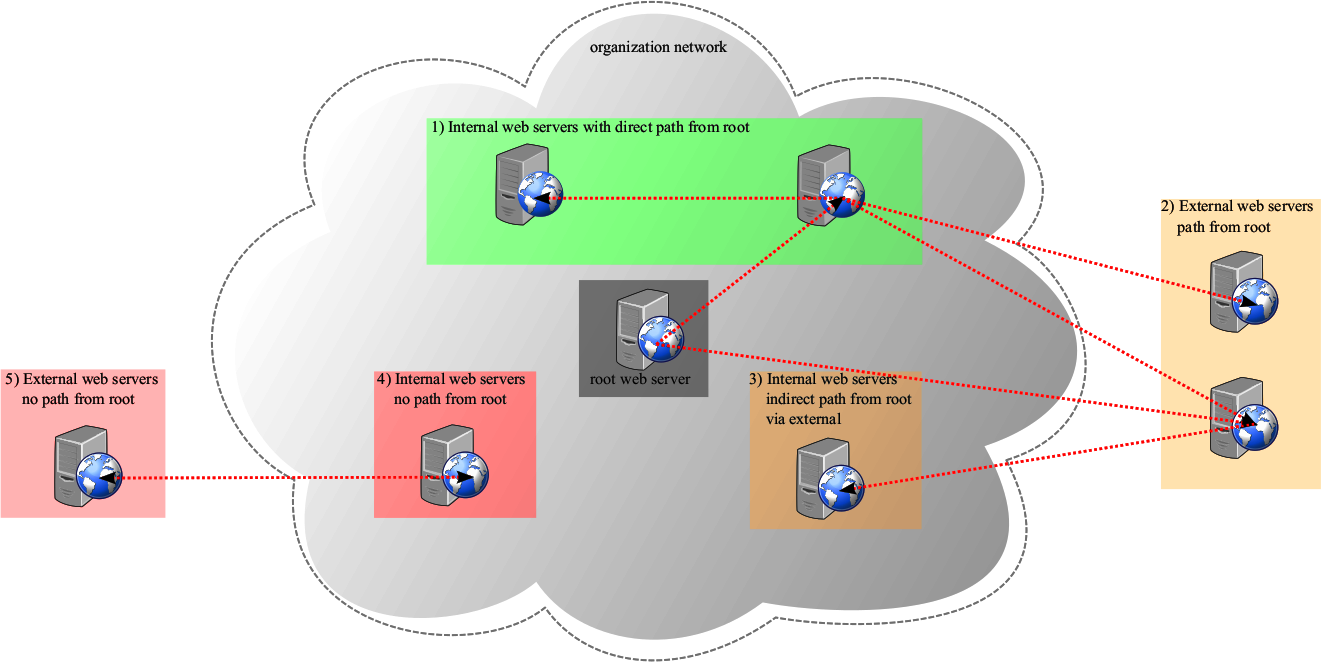
Abstract
Oftmals werden Organisationen und Forschungseinrichtungen wie Hochschulen und Universitäten durch viele verschiedene Domains repräsentiert, die auf mehreren Webservern gehostet werden. Dem Anwender sind diese oftmals nicht gänzlich bekannt, da Arbeitsgruppen, Institute, etc. ihre eigenen Domains und Webserver – unter Umständen auch extern gehostet – haben können. Für die Web-Archivierung in großen Organisationen stellt dies ein Problem dar, da a priori nicht bekannt ist, welche Domains archiviert werden müssen. Diese sollten automatisch erkannt werden. Das Hauptproblem dabei besteht darin, eine Zugehörigkeit von Domains zur Organisation festzustellen. Wir stellen verschiedene Verfahren vor, die vor und während des Harvestens angewand werden können, um dynamisch zu entscheiden, welche Domains dem Archiv hinzugefügt werden müssen.
BibTeX (Download)
@techreport{Zink2014AutomatischeDomains,
title = {Automatische Identifikation relevanter Domains zur Web-Archivierung},
author = {Thomas Zink and Oliver Haase and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2018/09/zink2014automatischedomains.pdf},
year = {2014},
date = {2014-10-01},
urldate = {1000-01-01},
number = {KN-2014-DISY-01},
institution = {University of Konstanz},
abstract = {Oftmals werden Organisationen und Forschungseinrichtungen wie Hochschulen und Universitäten durch viele verschiedene Domains repräsentiert, die auf mehreren Webservern gehostet werden. Dem Anwender sind diese oftmals nicht gänzlich bekannt, da Arbeitsgruppen, Institute, etc. ihre eigenen Domains und Webserver – unter Umständen auch extern gehostet – haben können. Für die Web-Archivierung in großen Organisationen stellt dies ein Problem dar, da a priori nicht bekannt ist, welche Domains archiviert werden müssen. Diese sollten automatisch erkannt werden. Das Hauptproblem dabei besteht darin, eine Zugehörigkeit von Domains zur Organisation festzustellen. Wir stellen verschiedene Verfahren vor, die vor und während des Harvestens angewand werden können, um dynamisch zu entscheiden, welche Domains dem Archiv hinzugefügt werden müssen.},
keywords = {Web Applications, Web Archiving},
pubstate = {published},
tppubtype = {techreport}
}






