
Abstract
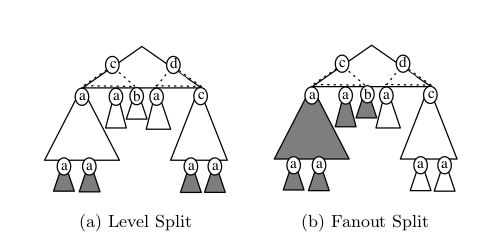
In contrast to relational databases the distribution of document-centric XML is not well researched. While there are some suggestions on how to split and distribute large XML documents, these approaches do not consider the parallel query evaluation. In this paper, we present and compare five different algorithms to search after suitable split nodes in
a large XML document. We then describe how to distribute extractable substructures over a fixed number of peers and how to query these peers in parallel to retrieve the final result. In addition, we analyse the impact of our splitting algorithms with respect to scalability for two different XPath expression classes on three well-known XML data sets. We conclude this paper with an outlook on future work, including result ordering during parallel query execution and dynamic re-distribution of XML fragments to new peers due to updates.
BibTeX (Download)
@inproceedings{Graf2008Distributing,
title = {Distributing XML with Focus on Parallel Evaluation},
author = {Sebastian Graf and Marc Kramis and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2008/graf08distributing.pdf},
year = {2008},
date = {2008-08-23},
urldate = {1000-01-01},
booktitle = {Sixth International Workshop on Databases, Information Systems and Peer-to-Peer Computing (DBISP2P 2008)},
pages = {55-67},
abstract = {In contrast to relational databases the distribution of document-centric XML is not well researched. While there are some suggestions on how to split and distribute large XML documents, these approaches do not consider the parallel query evaluation. In this paper, we present and compare five different algorithms to search after suitable split nodes in
a large XML document. We then describe how to distribute extractable substructures over a fixed number of peers and how to query these peers in parallel to retrieve the final result. In addition, we analyse the impact of our splitting algorithms with respect to scalability for two different XPath expression classes on three well-known XML data sets. We conclude this paper with an outlook on future work, including result ordering during parallel query execution and dynamic re-distribution of XML fragments to new peers due to updates.},
keywords = {Cloud Storage, XML},
pubstate = {published},
tppubtype = {inproceedings}
}






