
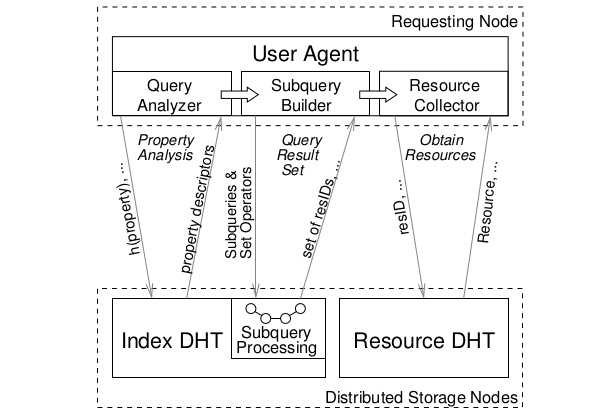
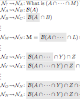
Abstract
Interest in distributed storage is fueled by demand for reliability and resilience combined with ubiquitous availability. Peer-to-peer (P2P) storage networks are known for their decentralized control, self-organization, and adaptation. Advanced searching for documents and resources remains an open problem. The flooding approach favored by some P2P networks is ineffiencient in resource usage, but more scalable and resource-efficient solutions based on Distributed Hash Tables (DHT) lack in query expressiveness and flexibility. In this paper, we address this issue and introduce new efficient, scalable, and completely distributed methods that strive to keep resource consumption by queries and index information as low as possible. We describe how to improve the handling of multiple subqueries combined through boolean set operators. The need for these operators is intensified by applications to go beyond simple exact keyword matches. We discuss, optimize, and analyze appropriate extensions to support range and prefix matching in DHTs.
BibTeX (Download)
@inproceedings{Bauer2004Bringing,
title = {Bringing Efficient Advanced Queries to Distributed Hash Tables},
author = {Daniel Bauer and Paul Hurley and Roman Pletka and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2004/bauer04bringing.pdf},
year = {2004},
date = {2004-11-01},
urldate = {1000-01-01},
booktitle = {Proceedings of IEEE LCN},
abstract = {Interest in distributed storage is fueled by demand for reliability and resilience combined with ubiquitous availability. Peer-to-peer (P2P) storage networks are known for their decentralized control, self-organization, and adaptation. Advanced searching for documents and resources remains an open problem. The flooding approach favored by some P2P networks is ineffiencient in resource usage, but more scalable and resource-efficient solutions based on Distributed Hash Tables (DHT) lack in query expressiveness and flexibility. In this paper, we address this issue and introduce new efficient, scalable, and completely distributed methods that strive to keep resource consumption by queries and index information as low as possible. We describe how to improve the handling of multiple subqueries combined through boolean set operators. The need for these operators is intensified by applications to go beyond simple exact keyword matches. We discuss, optimize, and analyze appropriate extensions to support range and prefix matching in DHTs.},
keywords = {Peer-to-Peer},
pubstate = {published},
tppubtype = {inproceedings}
}






