
-
How to block AI crawlers with robots.txt

If you wanted your web page excluded from being crawled or indexed by search engines and other robots, robots.txt was your tool of choice, with some additional stuff like <meta name=”robots” value=”noindex” /> or <a href=”…” rel=”nofollow”> sprinkled in. It is getting more complicated with AI crawlers. Let’s have a look.
-
«Right to be Forgotten» void with AI?

In a recent discussion, it became apparent that «unlearning» is not something machine learning models can easily do. So what does this mean to laws like the EU «Right to be Forgotten»?
-
Offline digital cash?

The question of using digital money in the event of a network outage comes up again and again. Here is an overview of the options and their pros and cons.
-
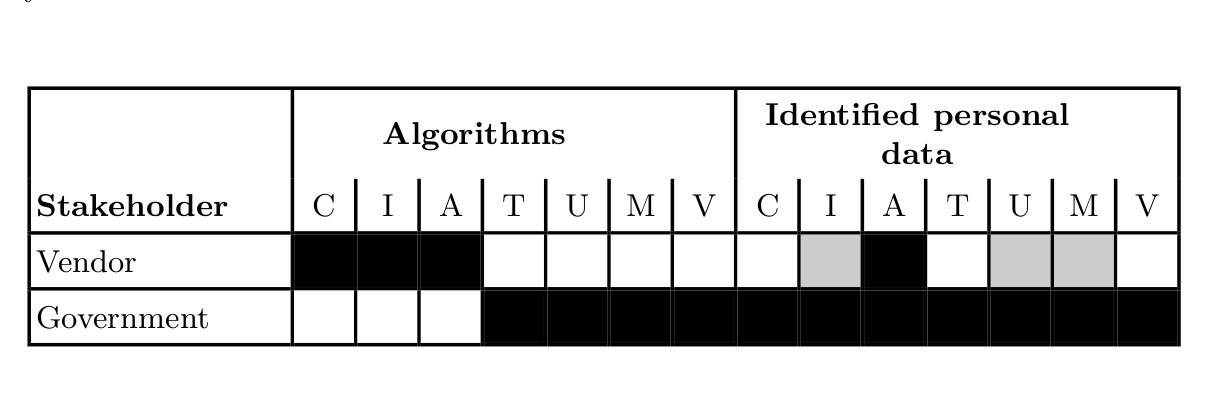
Requirements for legally compliant software based on the GDPR
-
Interoperable Chat in Your Web Browser: JSXC 3.0 released
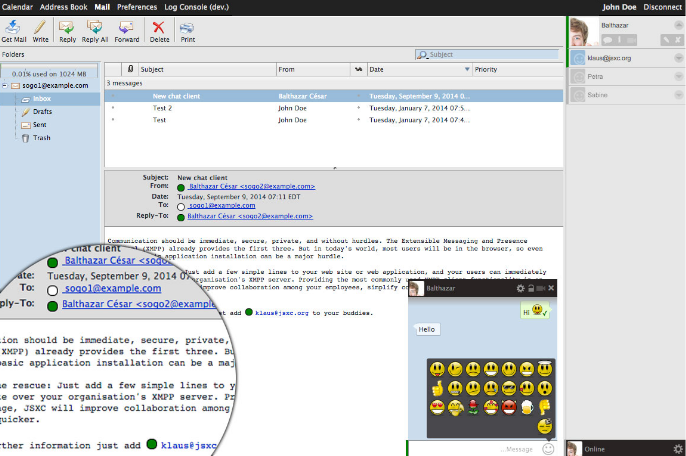
Open, standards-compliant and interoperable chat sounds like a boon. However, proprietary and closed systems (WhatsApp, Facebook chat, Google Hangouts, …) are often easier to deploy, as they are nicely integrated in existing ecosystems. The freshly-released JSXC 3.0 shows that this is not necessary.
-
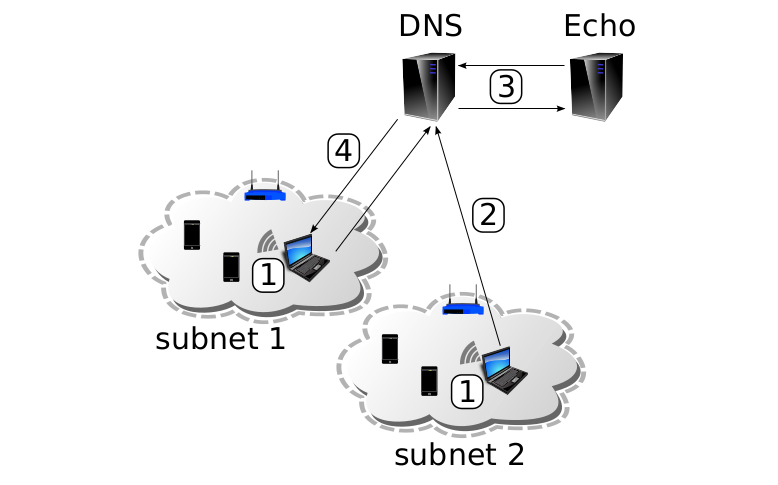
Stateless DNS
-
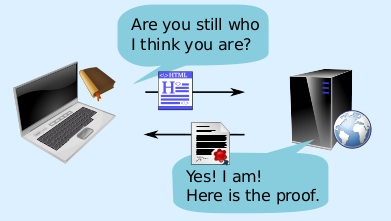
Boost DNS Privacy, Reliability, and Efficiency with opDNS Safe Query Elimination
-
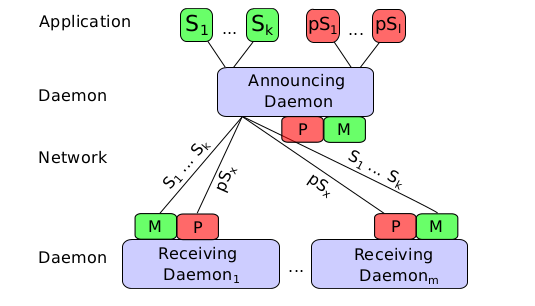
A Multicast-Avoiding Privacy Extension for the Avahi Zeroconf Daemon
-
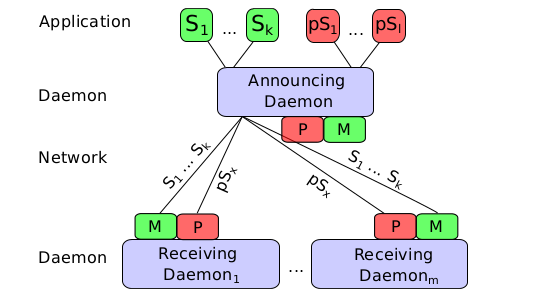
Efficient Privacy Preserving Multicast DNS Service Discovery
-
Adding Privacy to Multicast DNS Service Discovery
