
Abstract
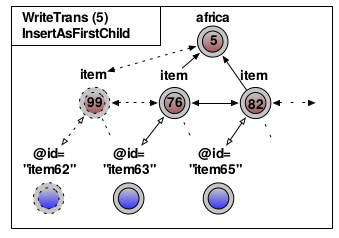
XML underlies the same constant modification scenarios like any other resource especially in flexible environments like the WWW. Therefore, intelligent handling of versioned XML is mandatory. Due to the structural nature of XML, the efficient storage of changes in the data and therefor in the tree needs new paradigms regarding efficient storage and effective retrieval operations. We present a node granular XML versioning approach which relies on the independence of the storage and the versioning system. Different layers which have the ability to satisfy specific aspects of a node-granular versioning storage guarantee this independence. Results prove that our architecture offers efficient handling of consecutive changes within all modification scenarios while not restricting XML regarding its usage. Hence, our prototype system handles even huge XML instances while ensuring equal access to each revision of the data.
BibTeX (Download)
@inproceedings{Graf2011Treetank,
title = {Treetank, Designing A Versioned XML Storage},
author = {Sebastian Graf and Marc Kramis and Marcel Waldvogel},
url = {https://netfuture.ch/wp-content/uploads/2011/graf11treetank.pdf},
year = {2011},
date = {2011-03-26},
urldate = {1000-01-01},
booktitle = {XML Prague '11},
abstract = {XML underlies the same constant modification scenarios like any other resource especially in flexible environments like the WWW. Therefore, intelligent handling of versioned XML is mandatory. Due to the structural nature of XML, the efficient storage of changes in the data and therefor in the tree needs new paradigms regarding efficient storage and effective retrieval operations. We present a node granular XML versioning approach which relies on the independence of the storage and the versioning system. Different layers which have the ability to satisfy specific aspects of a node-granular versioning storage guarantee this independence. Results prove that our architecture offers efficient handling of consecutive changes within all modification scenarios while not restricting XML regarding its usage. Hence, our prototype system handles even huge XML instances while ensuring equal access to each revision of the data.},
keywords = {Cloud Storage, XML},
pubstate = {published},
tppubtype = {inproceedings}
}






